
笔者上周末测试这个产品后感觉到了写代码和写科幻的双重失业危机,赶紧去看了下官方的博客和援引论文的信息。从 ChatGPT 的产品博客[1]来看,基本路线是在 175B 的 GPT-3 上使用人类反馈强化学习 (RLHF) 来强化对人类指令的识别 。
ChatGPT 惊艳的效果主要可以归功于三个方面:
先看看官网上从 GPT-3 到 InstructGPT-3 迭代路线[2],参考 OpenAI model index
GPT-3.5
2020年7月发布了175B的GPT-3[3],主要基于文本训练和通用任务训练。然后在2021年7月发布了12B的CodeX[4],主要基于代码训练。虽然这个模型没有直接使用,但它受到启发,提出了基于文本和代码混合数据训练的方法[5]。在GPT-3基础模型的基础上,通过175B的Code-davinci-002(davinci指的是175B大小系列)进行了两个阶段的训练,重点提高了意图识别的能力(InstructGPT)[7]。这两个阶段分别是:(1)prompt + human demo 数据有监督学习 和(2)和 reward model 交互采样做强化学习。这两个过程分别得到了text-davinci-002和text-davinci-003。关于这两个模型的训练,Blog提到,和今年1月份的文章InstructGPT中训练方法一致,只有在数据收集过程中有细微差别。
这三个模型统称为GPT-3.5系列,也是chatGPT背后的基石。GPT-3的参数量、数据和惊人的效果,以及CodeX的代码补全,无疑为整个chatGPT的语言能力、代码示例能力提供了基础。本文不再赘述。作者在研究生期间主要研究强化学习,重点讲述InstructGPT为什么可能有效,以及强化学习的优点和缺点。
InstructGPT 的目的是增强 GPT-3 对具体人类指令的响应效果,即给出 prompt 和输出文本之间的强相关性。
训练数据的Prompt 主要来自于 OpenAI 此前产品 API 中用户提交的 prompt 和标注者提供的两部分,形式和各项任务的分布如图。

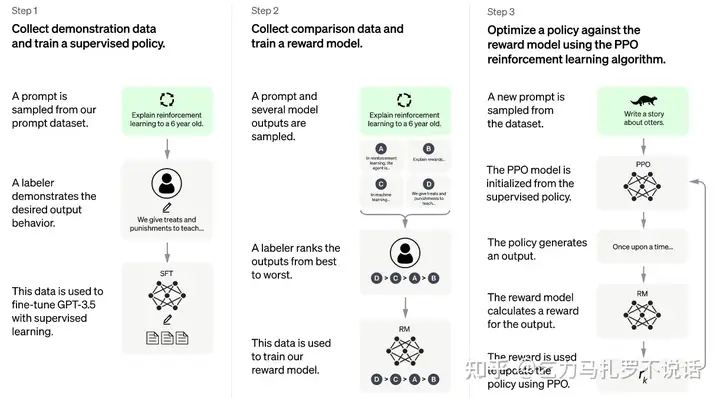
如上图所示,分为三个训练步骤