
笔者高度怀疑 New Bing 这么短的时间内能拿出的产品应该是有老工作的基础,最疑似的是 OpenAI 2021 年 12 月发布了 WebGPT,与 ChatGPT 底层技术的论文几乎前后脚发出、技术思路一脉相承的姊妹篇。本文会从 WebGPT 的技术思路出发,与 ChatGPT 和 Google LaMDA 进行一些分析对比。最后,也会探讨 Google 和 OpenAI 的技术立场。
习得知识有两类套路,一种是当模型足够大时,它能记住常识和相当多的语料中的隐式知识,比如 ChatGPT,另一种则是基于检索、数据库等的显性知识的注入,提升回答可靠性。这就是 WebGPT 和 LaMDA 等工作的想法。
WebGPT 的效果和看到的 New Bing 测试很像。比如,解释玛雅文明为啥衰亡,答曰,因森林砍伐和人口过剩。一段标准的 wiki 式解释及相关引用源,查看引用也比较规范。遗憾的是,还不是一个工程化的产品,没有提供可交互式的测试,仅有 ELI5 数据集的更多样例 Further Sample 。
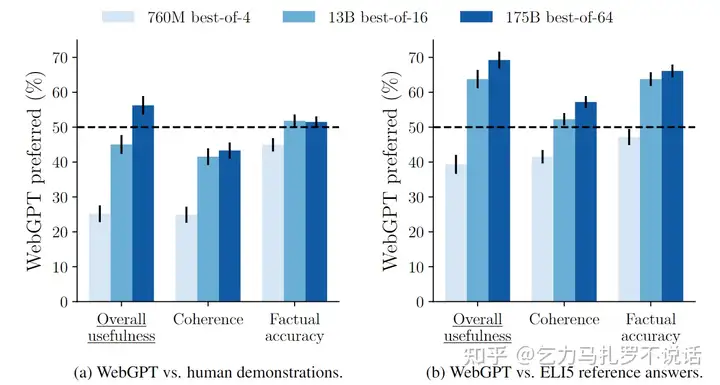
根据官方的两两盲测结果,WebGPT在事实性方面无论是7亿、130亿还是1750亿模型都能与人类答案持平甚至略胜。在连贯性方面,130亿和1750亿模型的胜率达到了40%左右,7亿模型到130亿有了一个飞跃。和参考答案相比,WebGPT在事实性和连贯性方面都有明显的优势。
首先,我们来看一下数据。WebGPT 对知识要求较高,因此没有使用 OpenAI API 接口用户的问题数据。相反,我们从现有的 ELI5(Explain like I am Five)中获取问题。该数据集来自 Reddit #把我当成五岁一样来解释标签,其中默认用户只具有基础语言能力和最少的常识。使用这些问题进行提问,并分别标注了两份数据:
怎么使用这些数据?WebGPT 和 ChatGPT 两者的相似之处就不用说了,从论文名的“with human feedback”的高度重合就可以看出师出同门。不仅都采用了 GPT-3 这个底座大模型,训练阶段和 ChatGPT 博客中指出的前三阶段几乎完全一样(参考上一篇解析乞力马扎罗不说话:从强化学习视角聊聊 ChatGPT)。
**第一阶段实质上就类似于 ChatGPT 的有监督微调(Supervised FineTune, SFT),但在序列问题建模上有一个核心区别。**WebGPT 使用的 demo 是标注者在检索中的一系列动作(如下图),而不是 ChatGPT 的多轮对话序列。 这可能也是为啥不采用已有明确含义的微调,而是改用模仿学习中的“行为克隆”。换句话说,这里的动作空间是 10 个检索动作构成的集合,并不是词表或句子的马尔可夫过程构成的语言空间,直观来看小了不是一个数量级。